
Content

A data lakehouse is a hybrid data architecture that keeps all your enterprise data in low-cost object storage while adding warehouse-grade governance, ACID transactions, and high-performance SQL analytics. For executives and platform architects, this model directly eliminates the expensive cycle of moving data between isolated systems. Consider this your definitive guide to data lake vs data warehouse vs lakehouse explained for executives.
If you are wondering why combine data lakes and data warehouses in modern data platforms, the answer comes down to cost control, operational speed, and simplified data governance. This article covers the core reference architecture, practical design patterns, and vendor approaches to help you decide exactly when should companies move from data warehouse to lakehouse. We will also outline how Multishoring can act as your technical implementation partner to guide your modernization journey.
Why Modern Data Platforms Need a Lakehouse
Historically, organizations relied on two distinct systems to handle their corporate analytics. Data warehouses managed clean, structured, and highly governed data specifically optimized for business intelligence (BI) reporting. Meanwhile, data lakes provided cheap, highly scalable storage for raw, diverse, and unstructured data used primarily by data science teams.
Maintaining these two isolated environments creates severe problems with separate data lake and data warehouse architectures. Engineering teams are forced to build and maintain brittle ETL (Extract, Transform, Load) pipelines just to synchronize data moving from the lake into the warehouse.
This traditional two-tier setup leads to several critical business issues:
- Data duplication: Copying data from the lake to the warehouse inflates cloud storage costs and creates conflicting versions of the truth.
- Slow time-to-insight: Forcing data through multiple system hops drastically delays reporting and machine learning workflows.
- Governance complexity: Applying consistent security rules is nearly impossible when the same datasets live under different access controls in multiple systems.
A unified platform directly removes these operational roadblocks. By keeping data in one open storage layer and applying a transactional metadata layer on top, it becomes clear how lakehouse architecture solves data silos and duplication across the enterprise.
Scaling your data architecture?
We provide end-to-end lakehouse implementation services, from platform selection and migration to unified governance and performance tuning. Let our architects help you eliminate data silos and build a scalable, future-proof analytics foundation.
Let us guide you through our data architecture assessment and modernization process.

Let us guide you through our data architecture assessment and modernization process.
From Data Lakes and Warehouses to Lakehouse
To understand why the industry is shifting toward a unified architecture, we must first look at the traditional patterns and the challenges they introduced for enterprise data teams.
Recap: Data Lakes and Data Warehouses
For years, architects relied on a two-tier strategy to balance cost and performance.
- Data Warehouse (Classic Pattern): Designed for structured, high-value data, the warehouse is the gold standard for BI and SQL-based reporting. It provides strong governance, schema-on-write integrity, and fast query speeds. However, it lacks the flexibility required for raw, semi-structured, or massive-scale data.
- Data Lake: Built on inexpensive, scalable object storage, data lakes use schema-on-read to ingest everything from raw logs to diverse file formats. While excellent for flexibility and cost, they often become a “data swamp” without robust metadata management and performance optimizations.
Commonly, organizations operated in a bifurcated environment: raw data lived in the lake, and engineers periodically copied curated subsets into the warehouse for executive dashboards, while data science teams attempted to run complex models directly off the lake.
Why Separate Lakes and Warehouses Create Problems
Managing two distinct architectures—a data lake and a data warehouse—results in “data gravity” issues that stall innovation. From our consulting experience, we see these recurring pain points in organizations using two-tier architectures:
- Data Silos and Inconsistent Truth: When data is copied between systems, discrepancies inevitably arise. Decision-makers often struggle to get a single source of truth because reports in the warehouse may not match the raw data in the lake.
- Costly Infrastructure and Pipelines: Maintaining complex ETL and ELT pipelines to move data from the lake to the warehouse consumes significant engineering time and inflates cloud compute costs.
- Governance Gaps: Security, lineage, and quality rules are notoriously difficult to sync across systems. Managing access controls in the lake vs. the warehouse results in audit compliance gaps and manual security overhead.
- Difficulty Scaling Workloads: Teams struggle to support both high-performance BI and advanced machine learning without duplicating massive datasets and their associated business logic.
These operational friction points are exactly what drive organizations to seek a more scalable architecture for data lake and warehouse integration.
What Is a Lakehouse (and How It Combines the Best of Both)
A data lakehouse is a unified data architecture that keeps all enterprise data in an inexpensive, scalable data lake while adding warehouse-grade features. By using open table formats and metadata layers (such as Delta Lake, Apache Iceberg, or Apache Hudi) on top of object storage, you gain ACID transactions, schema enforcement, and high-performance SQL analytics.
This architecture truly combines the best of both worlds:
- From Data Lakes: You retain low-cost, scalable storage and the ability to handle structured, semi-structured, and unstructured data with total openness.
- From Data Warehouses: You gain strong schema management, ACID consistency, optimized query performance, and rich support for traditional BI tools.
Different vendors implement these concepts in unique ways—such as Google’s BigQuery/BigLake, Databricks Lakehouse, or Snowflake’s unified storage model. Regardless of the specific provider, the goal is the same: providing a scalable architecture for data lake and warehouse integration that removes the need for brittle, multi-system pipelines.
The following diagram shows how data warehouses, data lakes, and lakehouses differ at a high level.
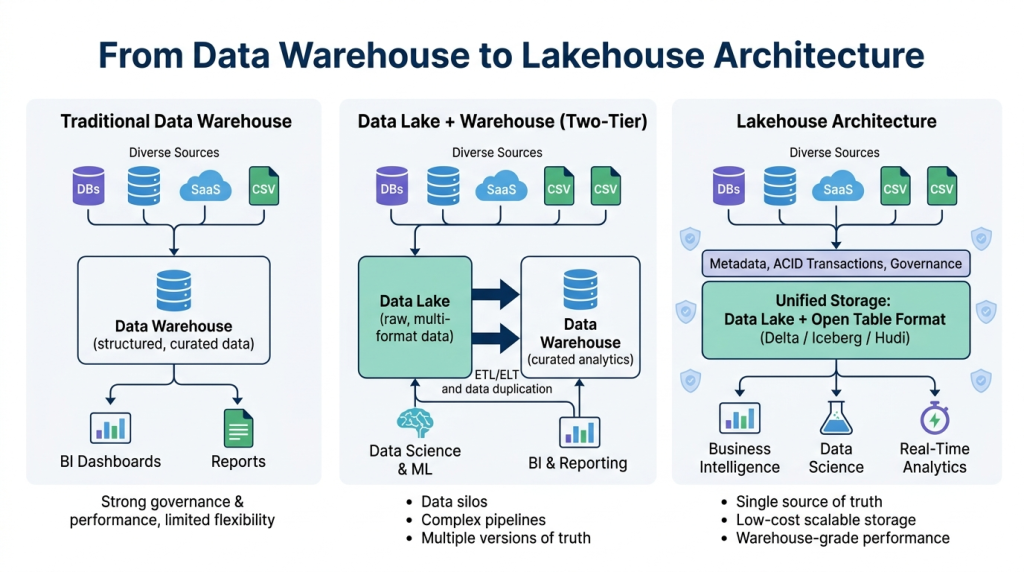
Lakehouse Reference Architecture & Key Components
Moving beyond the definition, successful implementation requires a clear, layered model. We view the lakehouse not just as a technology, but as a framework that ensures data flows seamlessly from raw intake to final business consumption.
Core Layers of a Lakehouse
While vendors often use different branding, the underlying technical architecture remains consistent. To scale your data infrastructure, align your design with these five logical layers:
- Ingestion Layer: This is your entry point. It handles high-velocity data from operational databases, SaaS applications, event streams (IoT), and flat files. Use tools like CDC pipelines, Kafka, or managed cloud ingestion services (e.g., Fivetran) to move data into your system without human intervention.
- Storage Layer (Data Lake): This represents your central, low-cost object storage (e.g., Amazon S3, Azure Data Lake Storage, or Google Cloud Storage). It serves as the foundation for both raw and processed data, utilizing decoupled compute and storage to ensure elastic, independent scaling.
- Table / Metadata Layer: This is the “brain” of the lakehouse. It uses open table formats like Delta Lake, Apache Iceberg, or Apache Hudi. These formats sit on top of your object storage to provide ACID transactions, schema enforcement, time-travel capabilities, and indexing—features once found only in traditional warehouses.
- Processing Layer: This layer executes your ETL and ELT workloads. It includes powerful SQL engines, Spark, Flink, and dbt. A best practice is to adopt a medallion architecture, which organizes data into Bronze (raw), Silver (cleaned/conformed), and Gold (highly curated/business-ready) layers.
- Consumption / API Layer: Finally, this is where business value is realized. BI tools, notebooks, and ML platforms access the same governed, curated tables, ensuring that everyone from an executive to a data scientist works from the same source of truth.
Unified Governance, Security, and Quality
One of the most common challenges in modern platforms is data silos. A lakehouse enables unified governance, replacing the need to manage policies separately for your lake and your warehouse.
- Data Catalog and Discovery: Implement a central catalog that maintains both business and technical metadata. This makes data findable and provides clear lineage, allowing users to trace how a specific KPI was calculated.
- Access Control and Security: Apply Role-Based Access Control (RBAC) across your entire schema. You should be able to enforce column-level or row-level security and implement automated data masking for PII (Personally Identifiable Information) from a single control plane.
- Data Quality & Validation: Treat quality checks as code. Embed automated tests within your pipeline—specifically during the transitions between Bronze, Silver, and Gold layers—to enforce schema validation, null checks, and referential integrity.
- Compliance and Auditability: Centralized logging ensures that every access request and data modification is tracked. This creates a transparent audit trail, which is essential for regulated industries and simplifies compliance reporting.
How Lakehouse Enables Multiple Workloads on One Platform
A key benefit of this architecture is its ability to support diverse workloads without duplicating datasets.
Previously, if you wanted to run a BI dashboard and a predictive machine learning model on the same data, you often had to create two separate, static copies—one for the warehouse and one for the lake. This leads to drift and technical debt.
A lakehouse eliminates this. Because the data is stored in open, performant formats, your BI tools can run ad hoc SQL analytics on the same tables that your data scientists use for training complex ML models. This support for varied data types—including structured logs, semi-structured JSON, and unstructured images or text—allows you to handle batch and real-time streaming analytics on one unified platform.
Our Data Consulting Services You Might Find Interesting

Data Warehouse Consulting Services
We design, build, and modernize data warehouses that bring order to your fragmented data.

Modern Data Architecture Services
We design and implement data architectures that replace aging legacy systems with a scalable cloud foundation.

Data Governance Consulting & Integration
We help you build a practical system of trust around your information. We work with you to make sure your data is accurate.
Implementation Patterns, Best Practices, and Pitfalls
Transitioning from a legacy two-tier system (a separate lake and warehouse) to a lakehouse is rarely a “big-bang” migration. Most successful enterprise projects adopt a phased, pragmatic approach to modernization.
Migration and Coexistence Patterns
Whether you are starting fresh or modernizing an existing legacy environment, you have two primary paths:
- Greenfield Design: You build your lakehouse from scratch on your preferred cloud platform. This allows you to prioritize modularity, open table formats, and a clean medallion architecture (Bronze-Silver-Gold) from day one.
- Brownfield Integration: You integrate the lakehouse alongside your current warehouse. You might keep the legacy warehouse for mission-critical, high-performance BI reporting while building out new data products and ML workloads directly in the lakehouse. Over time, you gradually back-migrate your curated tables to the lakehouse as trust and capability grow.
Design & Modeling Best Practices
A lakehouse does not remove the need for good data modeling. In fact, it provides a better foundation for it. We recommend using dimensional modeling or data-vault styles for your curated Gold layer to ensure consistency across all BI tools.
To help you choose the right approach for your specific data maturity level, refer to the following framework:
| Strategy Element | Traditional “Two-Tier” | Lakehouse Modernization |
|---|---|---|
| Data Storage | Siloed (Lake & Warehouse) | Unified (Object Storage) |
| Data Duplication | High (ETL/ELT to sync) | Minimal (Single source of truth) |
| Schema Management | Schema-on-Write (Warehouse) | Flexible (Schema Evolution) |
| Governance | Duplicated across systems | Centralized & Automated |
| Best For | Legacy batch reporting | BI, AI, ML & Real-time analytics |
Performance Optimization Tip: To keep queries fast, focus on partitioning and clustering (or Z-ordering) within your table formats. This ensures that your engine only scans the data it absolutely needs, which significantly reduces query latency and costs.
Governance, Quality, and Cost Management
When scaling, the “data swamp” risk is real. You must operationalize governance to avoid the same mess that plagued early data lakes.
- Governance Operating Model: Do not just buy a tool. Define clear roles: data owners, stewards, and a dedicated platform team. These stakeholders must agree on policies and decision-making processes before you load the first table.
- Data Quality as Code: Automate your testing. Integrate quality checks directly into your CI/CD pipelines. If a dataset fails a null-check or completeness threshold at the transition from Bronze to Silver, the pipeline should alert the team immediately rather than poisoning your Gold layer.
- Cost Governance: Treat your cloud infrastructure like a business asset. Use lifecycle management to move older, inactive data to colder, cheaper storage tiers. Most importantly, implement auto-scaling and ensure your compute clusters are configured to shut down when idle.
From our experience, the biggest pitfall is ignoring workload isolation. Do not run your heavy, unpredictable data science model training on the same compute cluster that powers your mission-critical executive dashboards. Even in a unified lakehouse, use separate compute clusters for different workload types to ensure consistent performance.
Use Cases, Vendor Ecosystem, and How to Choose
The theoretical benefits of a lakehouse only matter when they translate into measurable business outcomes. By unifying data, your team can pivot from “keeping the lights on” in brittle infrastructure to accelerating high-value analytics.
High-Value Use Cases for Lakehouse
When considering a migration, we recommend starting with a pilot program focusing on one of these high-impact areas:
- Unified Analytics (BI + ML): Eliminate the “two-version” problem where data scientists use one dataset and the marketing team uses another. A lakehouse allows both teams to access the same governed, gold-tier tables, ensuring consistent insights across the board.
- Customer 360 & Personalization: Bringing together large volumes of behavioral web traffic (from the lake) with CRM and transactional data (from the warehouse) is significantly faster in a unified environment, enabling real-time personalization.
- Real-Time Analytics: Use streaming ingestions to feed data directly into your lakehouse. This is vital for fraud detection or operational monitoring where waiting for a batch ETL window is simply not an option.
- AI/ML Scale: Machine learning models are data-hungry. Providing them with a seamless view of both raw, unstructured data and curated, structured data enables deeper feature engineering and faster training cycles.
Overview of Major Lakehouse Approaches
The market for modern data platforms is evolving quickly. While specific vendor features differ, they all converge on the same core principles: an open, governed storage layer, a robust metadata layer, and multi-workload compute.
- Databricks: Known for their deep roots in data engineering and Apache Spark, their platform is highly optimized for organizations that need a “code-first” approach and heavy ML capabilities.
- Snowflake: Historically a warehouse-centric platform, Snowflake has aggressively adopted lakehouse-style capabilities, making it an excellent choice for organizations that want to leverage their existing SQL expertise while keeping data in open formats.
- Google Cloud (BigQuery + BigLake): This approach offers deep integration with the Google ecosystem, utilizing BigLake to provide unified governance over data stored in object storage and warehouse-native tables.
- AWS / Azure (Redshift, Synapse, Fabric): Major cloud providers have built proprietary layers (like AWS Lake Formation or Microsoft Fabric) to bridge the gap between their storage and compute, offering deep integration if your existing stack is already locked into one cloud provider.
How to Choose and Where Multishoring Fits
Choosing a platform is a balance of your current cloud commitments, team skill sets, and future-proofing needs.
Decision Factors:
- Ecosystem: Are you already committed to AWS, Azure, or GCP? The “path of least resistance” often involves staying within your existing provider’s ecosystem.
- Openness: Do you require vendor-neutral table formats (Iceberg, Delta) to avoid future lock-in?
- Skill Set: Does your team prefer SQL, Python, or a GUI-based interface?
The Role of an Independent Partner:
An independent implementation partner like Multishoring helps bridge the gap between “technology” and “business value.” We guide you through vision and roadmap workshops, architecture blueprints, and pilot implementations. Our role is to ensure your migration is industrial-strength—covering everything from landing zones and security governance to CI/CD enablement.
If you are currently evaluating your options, we help you bypass the “sales pitch” to identify the specific architecture that aligns with your performance goals, regulatory needs, and budget.
Summary & Key Takeaways
The industry has moved beyond the “lake vs. warehouse” debate. Modern enterprises require the flexibility of a lake and the governance of a warehouse—a requirement that makes the lakehouse the default choice for modern data platforms.
Key Takeaways:
- Separate Systems are a Liability: Managing two distinct tiers leads to expensive data duplication, complex ETL maintenance, and fragmented governance.
- Unified Architecture is the Solution: A lakehouse uses open metadata layers to provide ACID compliance and performance on low-cost object storage.
- Modernization is Iterative: You do not need to replace everything overnight. Start with a greenfield project or a phased brownfield migration of your most critical workloads.
- Governance is Non-Negotiable: To avoid a “data swamp,” you must implement automated quality checks, clear ownership roles, and centralized security from the start.
Ready to modernize your data platform?
If you are struggling with data silos or escalating cloud costs, let’s talk. Our team at Multishoring specializes in designing and implementing scalable lakehouse architectures that deliver results.
Get in touch today to schedule a readiness assessment or to discuss how we can help you build your unified data strategy.











