
Content

The fastest way to ruin a million-dollar IT project is to build it on bad data. When companies plan a massive cloud migration or launch a new Artificial Intelligence initiative, they usually focus on the technology. They buy the best software and hire top developers. But they ignore the raw material.
Bad data compounds risk. If you migrate flawed records to the cloud, you simply create a more expensive mess. If you train an AI model on inconsistent history, the algorithm will make bad decisions at a terrifying speed.
Across industries, migration and AI best-practice guides consistently report that most overruns and failures are caused not by infrastructure choices, but by underestimated data quality and governance work. That’s why leading vendors and frameworks explicitly position data profiling and cleansing as mandatory early phases in any serious data migration or AI initiative.
To protect your investment, you must follow a strict sequence: profile first, clean second, then migrate or train.
What Does Data Profiling Actually Reveal?
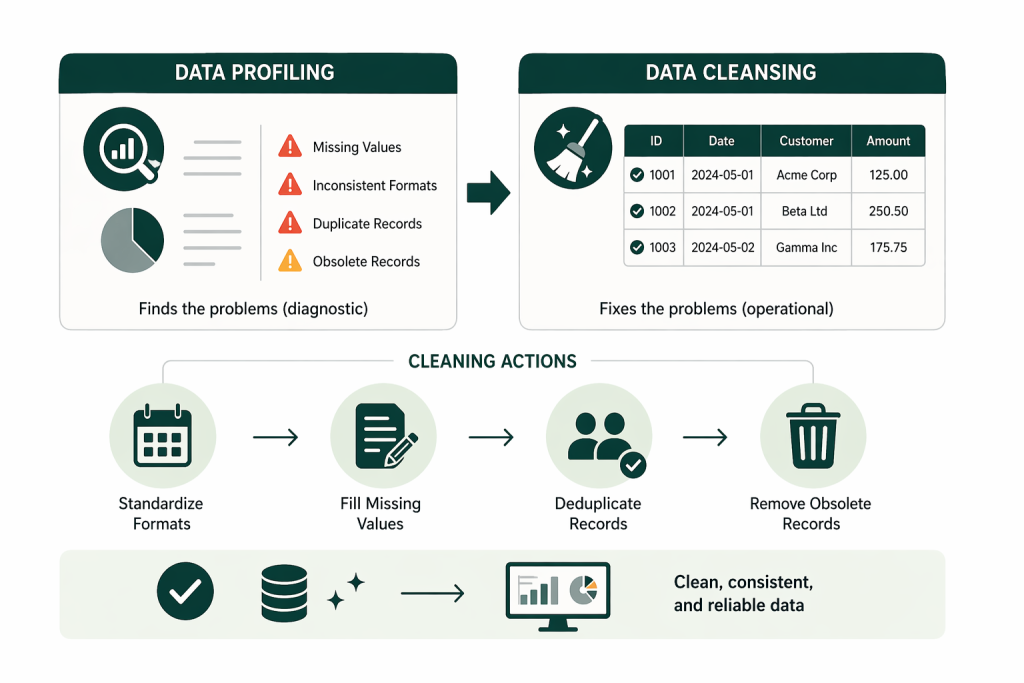
Data profiling is a diagnostic scan that exposes the factual reality of your database, showing you exactly what is broken, missing, or inconsistent before you start moving files. Major data and analytics vendors define profiling as the statistical and structural analysis of source data to understand its quality, structure, and relationships prior to use in analytics, migration, or AI.
Many IT leaders assume they know what their data looks like. Profiling proves those assumptions wrong. It scans the source systems and provides a statistical baseline of your data health. It tells you that 15% of your customer records lack an email address, or that you have 40 different spellings for the same product name. In real-world migration and quality assessments, it is common to uncover double‑digit percentages of missing or invalid values in critical attributes and widespread duplication of key entities across systems.
Which Data Quality Metrics Matter Most?
To understand your baseline, profiling tools measure several specific categories of data health.
- Completeness: Are mandatory fields empty?
- Uniqueness: How many duplicate records exist in the system?
- Validity: Do the values match the expected format? (e.g., Is there text in a numeric field?)
- Referential Integrity: Do child tables have matching parent records, or are there orphaned files?
These dimensions map directly to the core data quality categories – completeness, uniqueness, validity, and integrity – that underpin most modern data governance and data quality frameworks.
By identifying these issues early, you stop them from crashing your migration later.
Is your data ready for migration or AI?
Do not build expensive projects on broken data. Our experts run deep data profiling scans and execute cleansing strategies to remove risk before your migration or AI initiative begins.
Stop data errors early.

Stop data errors early.
How Is Data Cleansing Different from Profiling?
Data profiling finds the problems, while data cleansing actually fixes them. This reflects standard industry practice: profiling is treated as a diagnostic activity, and cleansing as the operational step that applies business rules to correct, standardize, and deduplicate records.
Once you have the diagnostic report from the profiling phase, you begin the remediation phase. Data cleansing is the physical act of repairing the dataset so it is fit for use in downstream systems.
This process involves standardizing formats, like forcing all dates into a YYYY-MM-DD layout. It involves filling in missing values where possible. It also includes deleting obsolete records that no longer serve a business purpose, reducing your future storage costs.
Can You Automate the Data Cleansing Process?
Yes, but only after you define clear business rules. Modern data quality and profiling platforms can automate large parts of cleansing – such as standardization, pattern enforcement, and deduplication – at scale.
You can use software to automate the standardization of states (changing “Texas” and “Tex” to “TX”). However, technology cannot make business decisions. If you have two records for “John Smith,” an algorithm cannot tell you which address is correct. You need human data stewards to set the rules that guide the automated cleansing tools. Leading governance guidance stresses exactly this division of labor: tools execute rules, but domain stewards own and refine those rules over time.
Why Does a “Lift and Shift” Migration Usually Fail?
Moving unprofiled data directly to a new system guarantees that old errors will break your new applications.
A “lift and shift” approach sounds fast and cheap. You just copy the database and paste it into the cloud. But legacy systems hide decades of workarounds, temporary fixes, and formatting errors. If you move this garbage into a modern platform, the new platform will reject it.
Modern migration frameworks explicitly call out “lift and shift” without prior profiling as a major anti‑pattern, because uncleaned legacy data is a leading cause of mapping errors, target rejects, and costly rework during cutover.
How Does Bad Data Break Source-to-Target Mapping?
If you write migration code based on assumptions instead of profiled reality, the target database will fail.
Migration engineers write rules to map data from the old system to the new one. They might write a rule that expects a 5-digit zip code. If the profiling phase was skipped, they will not know that the old system contains 9-digit zip codes and blank spaces. When the migration script runs, it hits these unexpected values, throws an error, and the entire transfer halts. Profiling prevents this expensive rework.
Why Do AI Projects Demand a Higher Standard of Data Quality?
Machine learning models learn entirely from historical data; if that history is flawed, the predictions will be dangerously wrong.
Standard Business Intelligence (BI) dashboards summarize data. If a dashboard is off by 1%, a human reader can often catch the context and ignore it. AI does not have human context. It treats every piece of data as a hard fact. High-quality data is an absolute precondition for sustained AI success.
Major AI and data platform providers echo this view: IBM, for example, explicitly frames AI data quality and governance as prerequisites for trustworthy AI, emphasizing that poor data directly undermines model reliability and business value.
What Happens When You Train AI on Dirty Data?
Training an algorithm on unverified, incomplete data generates hallucinations, biased behaviors, and wasted computing power.
If your historical sales data contains duplicate orders, the AI will predict artificially high demand. You will overstock your warehouse based on a lie. Profiling and cleansing are not optional “extras” for AI projects. They are the core risk controls that dictate whether the model will be a success or a failure. Industry guidance on AI data quality repeatedly warns that noisy, biased, or incomplete training sets are primary causes of unreliable models, wasted compute, and failed AI initiatives.
Our Data Consulting Services You Might Find Interesting



How Do You Build a Trustworthy Data Baseline?
You build trust by following a disciplined, four-step process that prepares your data before any development begins.
At Multishoring, we guide clients through this exact framework to de-risk their high-budget IT initiatives.
- Data Discovery: We identify all your source systems, tables, and dependencies to define the project scope. Data migration and governance reference architectures treat discovery and inventory as the first step in any modernization effort.
- Data Profiling: We run the diagnostic scan to measure completeness, uniqueness, and pattern consistency. This aligns with best practices that recommend robust profiling to inform mappings, transformations, and quality rules.
- Data Cleansing: We standardize formats, remove duplicates, and apply your business rules to fix the errors. This step operationalizes data quality policies and ensures that data loaded into the target platform meets agreed standards.
- Validation: We run a final check to confirm the cleansed data meets the strict requirements of your new cloud platform or AI model. Migration validation guides emphasize this stage to catch any residual issues and to prove that source‑to‑target mappings and quality rules work as intended.
This four‑step sequence reflects best practices seen in modern data migration and governance frameworks, which recommend systematic discovery, profiling, cleansing, and validation before changing platforms or deploying AI.
Through our Data Quality Consulting and Modern Data Architecture Services, we stop treating data preparation as an afterthought. We make your migration and AI programs predictable by making your data trustworthy first.











